Was ist das Feature von Windows 10, an dem sich die meisten Geister derbe scheiden? Richtig: das automatische Update, welches man nur verschieben, aber nicht beliebig aufschieben kann. Irgendwann muss man einfach das Update fahren, ob es nun für einem Sinn macht oder eben nicht! Die einzige Abhilfe ist es, seinen Rechner ohne Internet zu betreiben, aber wer macht das heute noch?!?
Sicherheitsexperten fanden diese Änderung einfach toll, weil so der Benutzer endlich gezwungen wird, wichtige Sicherheitsaktualisierungen relativ zeitnah einzuspielen. In Wirklichkeit aber ist diese Funktion ein Riesendesaster und hat zu einer Menge an Unmut gegenüber Microsoft geführt, weil das Update entweder immer genau dann gefahren wird, wenn man es am wenigsten braucht oder aber möglicherweise ein größeres Update erst einmal ungefragt gewisse Treiber und Programme kaputt macht. So oder so, es entreißt dem Benutzer ein gutes Stück der Kontrolle über den eigenen Rechner und ist in der Praxis einfach nur eine richtig üble Idee.
Man könnte also aus den Fehlern von Microsoft lernen und das sein lassen. NirvanV Dean mit seinem Black Dragon Viewer aber machte genau das Gegenteil: er hat diesen um eine automatische Updatefunktion erweitert. Diese ist ab Version 2.5.6 aktiv, der Download findet im Hintergrund statt und irgendwann ploppt dann von Windows eben die Meldung auf, dass sich der Black Dragon Viewer aktualisieren will. Das kann man dann tun, man kann es auch sein lassen, nur dann funktioniert nach dem Autor eben der Login vom alten Viewer nicht mehr. Also wird hier ein Zwang auf den Benutzer ausgeübt, die Aktualisierung vorzunehmen.
Der Grund dafür ist, dass dem Autor der Supportaufwand für seine alten Viewer einfach zu groß wird. Das ist noch bis zu einem gewissen Grad verständlich; aber dann kann man genau so gut sagen, dass es eine neue Version gibt, in der der Fehler behoben ist und fertig ist die Laube.
So aber zeigt der Autor hier eine Attitüde, die einfach nur noch zum Himmel stinkt. Er meint, besser als seine Benutzer zu wissen, welche Viewerversion von seinem Produkt sie genau haben wollen – nämlich immer die aktuellste – und ihnen das diktieren zu können. Wie man schon an Microsoft gesehen hat, kann und wird genau dies nicht gut gehen und für eine riesige Menge an Ärger sorgen.
Es ist nämlich nichts anderes hier als die Bequemlichkeit des Autors, die ihn letztendlich zu diesem Schritt bewogen hat – und seine Benutzer dürfen es nun ausbaden und nicht wenige werden darunter leiden.
Dazu kommen noch seine pampigen Reaktionen darauf, wenn sich nun Benutzer darüber beschweren, wie beispielsweise hier von Penny Patton:
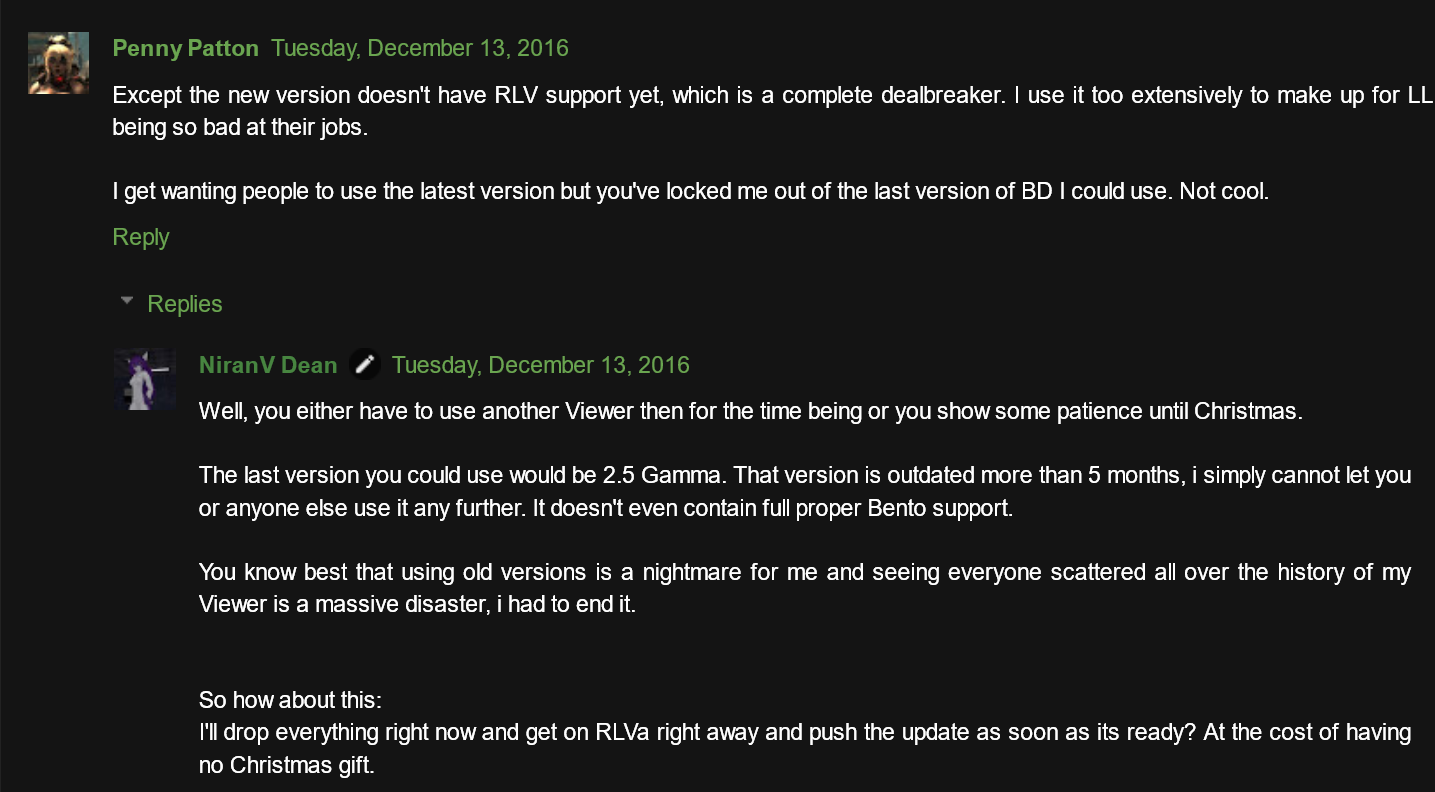
Vielleicht wäre NiranV Dean einfach besser damit beraten, da ihm seine Benutzer ja so auf den Keks gehen, wenn er die Entwicklung seines Viewers gleich einstellt. Dann muss er nämlich nicht mehr unter deren Wünschen und Problemchen leiden… in seinem „Monthly Writeup“ vom Oktober und November wird diese Änderung jedenfalls nicht erwähnt, noch im Changelog zu 2.5.6. Gut, es gibt den Blogpost, aber das sieht für mich wenigstens aktuell so aus, als wäre das Feature zunächst stillschweigend aktiviert wurden, bis es genügend Downloads gab und erst dann wurden die Benutzer benachrichtigt.
Da kommt doch so richtig vorweihnachtliche Freude auf. Ganz im Ernst: wer bisher noch den Black Dragon Viewer benutzt, der sollte sich mal so langsam nach einer brauchbaren Alternative umsehen, denn mit der Attitüde und dem absolut unprofessionellem Gehabe von NiranV Dean werdet ihr nie mehr sicher sein können, ob der Viewer nach dem nächsten Update noch funktioniert, wie ihr es braucht und wollt, oder eben nicht.
Kloppt ihn endlich in die Tonne und erlöst ihn so von seinem Leid!
